Kafka部署手册
Step1 下载kafka
下载1.1.0版本,在服务器解压
1 | tar -zxvf kafka_2.11-1.1.0.tgz |
下载地址如下
kafka download url
Step2 启动服务
运行kafka需要zookeeper的支持,所有需要优先启动zookeeper,如果你没有zookeeper可以使用kafka自带的。
1 | bin/zookeeper-server-start.sh config/zookeeper.properties |
为了方便我是使用docker进行拉起,仅供测试没有部署zookeeper集群。1
docker run --name kafka-zookeeper -p 2181:2181 -d zookeeper:latest
下面启动kafka服务1
bin/kafka-server-start.sh config/server.properties
执行命令后,kafka启动
创建一个Topic
创建一个名为dcits0的topic
1 | bin/kafka-topics.sh --create --zookeeper 10.88.2.110:2181 --replication-factor 1 --partitions 1 --topic dcits0 |
这里面只选择了一个分区和一个备份,这里只用一个备份的原因是我们目前只有一个broker在运行中。
创建成功后,我们通过命令1
bin/kafka-topics.sh --list --zookeeper 10.88.2.110:2181
可以看到我们刚刚创建的topic

同时我们还可以使用命令来查看这个topic的详情1
bin/kafka-topics.sh --describe --zookeeper 10.88.2.110:2181 --topic dcits0
结果为

我们可以看到只有一个备份副本以及一个partition,由于在server.properties中默认的broker.id=0,这里leader就是这个broker0,同时备份的replicas列表也只有他自己,Isr表示正在同步备份的节点,同样也只有他自己。
刚好在这里说下在命令中出现的几个概念:
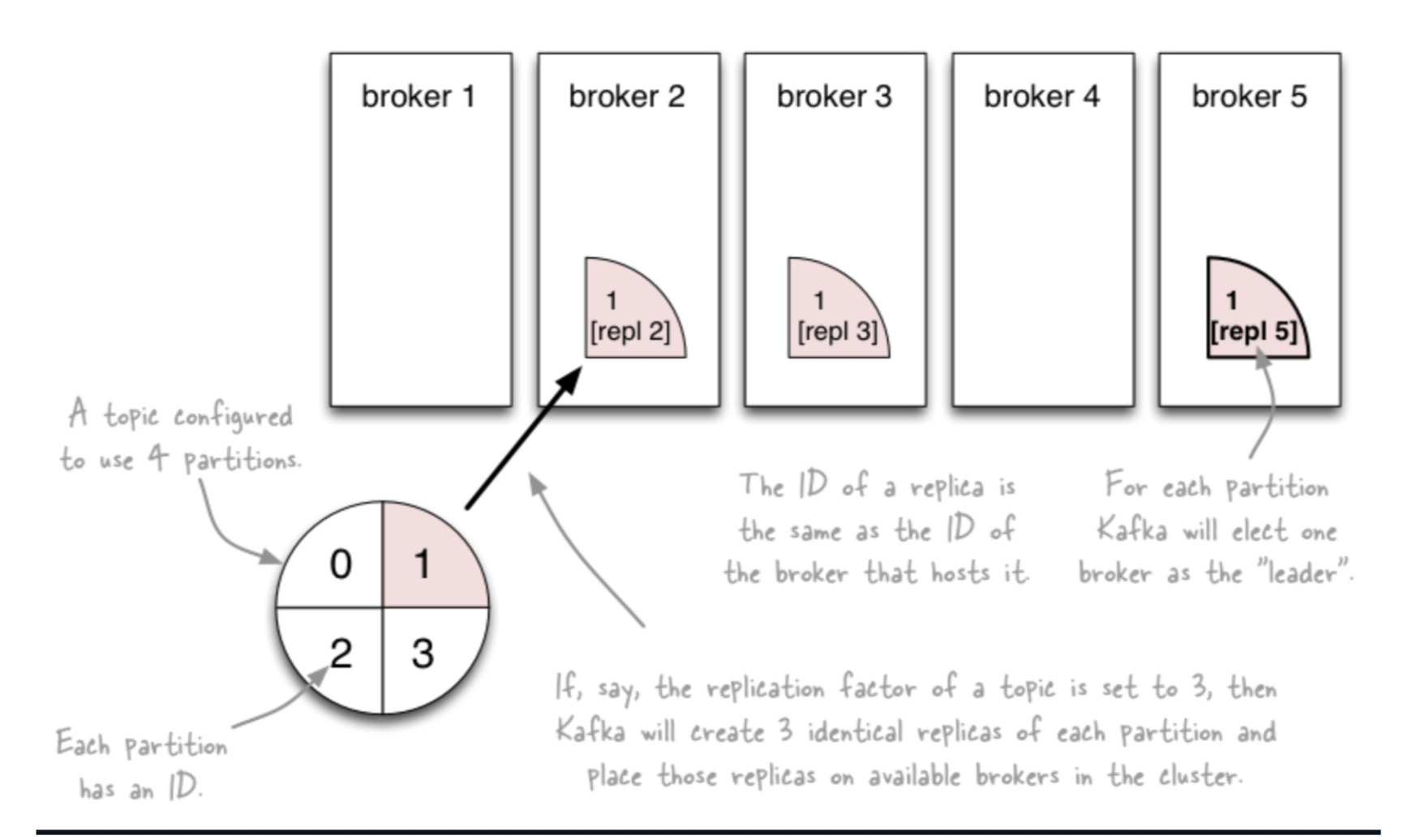
--replication-factor
这个参数是针对partition级别的,kafka通过创建topic时可以通过–replication-factor配置partition副本数。配置副本之后,每个partition都有一个唯一的leader,有0个或多个follower。
一般情况下partition的数量大于等于broker的数量,并且所有partition的leader均匀分布在broker上。
--partitions
partition是kafka里面的一个重要概念,这里就多说几句。
partition是topic物理上的分组。每个topic包含一个或多个partition,创建topic时可指定parition数量。每个partition是一个有序的队列,对应于一个文件夹,该文件夹下存储该partition的数据和索引文件。在发送一条消息时,生产者可以指定这条消息的key和分区机制来发送到不同的分区。
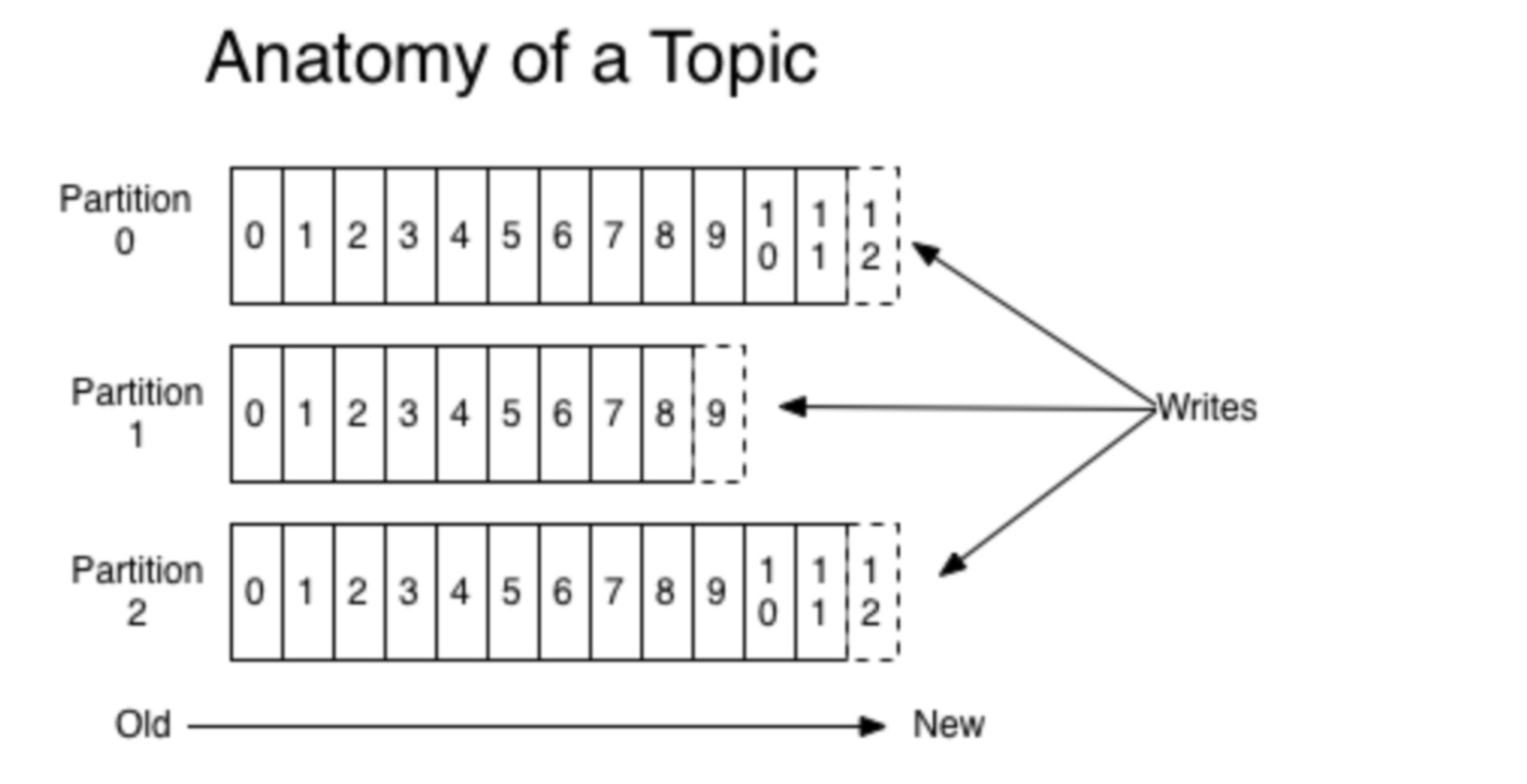
每个parition都是一个有序的,不可修改的消息队列,也正因为它是顺序写入所以才造就了kafka的大吞吐的能力。
partition内部有序
Kafka仅仅提供提供partition之内的消息的全局有序,在不同的partition之间不能担保。partition的消息有序性加上可以按照指定的key划分消息的partition,这基本上满足了大部分应用的需求。如果你必须要实现一个全局有序的消息队列,那么可以采用Topic只划分1个partition来实现。但是这就意味着你的每个消费组只能有唯一的一个消费者进程。
关于他们的关系,下面这张图应该表达的更加明确一些
Step4 发送消息
发送消息可以使用kafka官方提供的脚本,同时也可以自己通过kafka提供的各种语言的客户端发送消息
1 | bin/kafka-console-producer.sh --broker-list 10.88.2.110:9092 --topic dcits0 |
使用脚本进入console交互页面,输入要发送的消息

Step5 消费消息
同样发送消息可以使用kafka官方提供的脚本,脚本只是一个验证,在正式环境还是需要使用其提供的客户端,毕竟涉及到多个消费者同时消费消息的场景
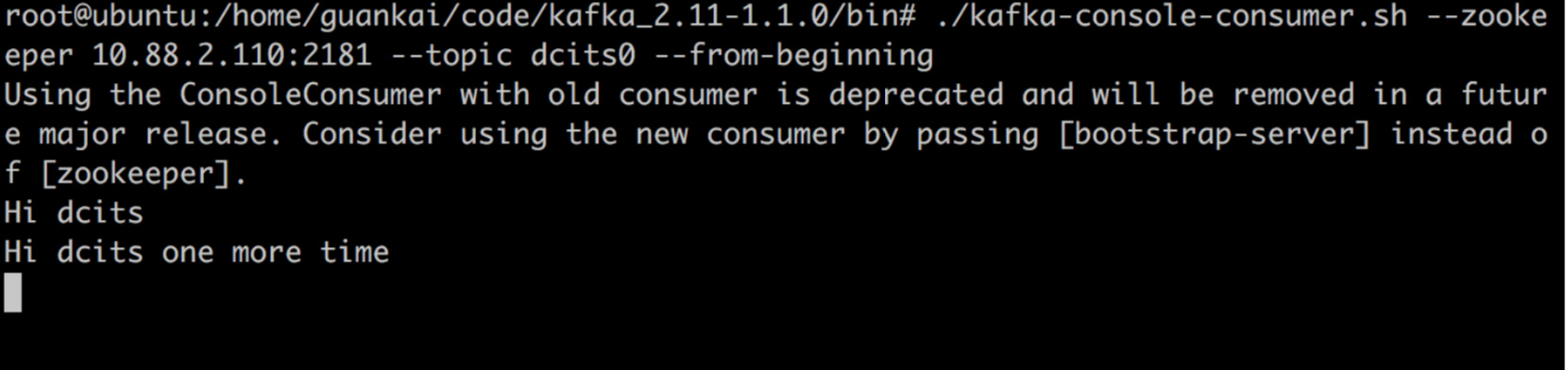
1 | bin/kafka-console-consumer.sh --zookeeper 10.88.2.110:2181 --topic dcits0 --from-beginning |
可以该topic保留的从头开始数据,一般的客户端都会记录offset(偏移量),不会重复消费消息。
执行该命令后可以看到之前写入的两条记录
Step6 集群部署
kafka只有一个broker的时候,无法体现它强大的能力,所以需要多拉起几个broker,组成集群
由于条件有限,我只能在一个虚拟机上部署3个broker,正式环境中,我们应该把节点分散在不同的机器上,一方面是为了某一个节点物理宕机可以保证集群不受影响,另一方面是由于kafka对IO的要求很高。
首先为新的broker准备配置文件
1 | cp config/server.properties config/server1.properties |
编辑文件这两个文件主要设置以下的参数
1 | config/server1.properties |
其中broker.id是集群中每个节点的唯一标识
通过下面命令来启动两个新的broker,server.properties里面的zookeeper.connect参数指向的是localhost:2181,所以此处不用再做修改
1 | /bin/kafka-server-start.sh config/server1.properties & |
接着创建一个新的topic,设置partition为1,其备份数为31
/bin/kafka-topics.sh --create --zookeeper 10.88.2.110:2181 --replication-factor 3 --partitions 1 --topic my-topic
创建完成后,我们来看下集群的详情是什么情况
我们可以ReplicationFactor数量是3,其中topic的partition的leader是在broker 0上,备份的partition有0,1,2,同步备份的也是0,1,2
下面我们来尝试以下集群的容错
首先给topic写入数据
1 | bin/kafka-console-producer.sh --broker-list 10.88.2.110:9092 --topic dcits-topic |

我们通过脚本消费该信息
1 | bin/kafka-console-consumer.sh --zookeeper 10.88.2.110:2181 --topic dcits-topic --from-beginning |
可以获取到对应的信息

接着我们把刚刚写入的broker停掉
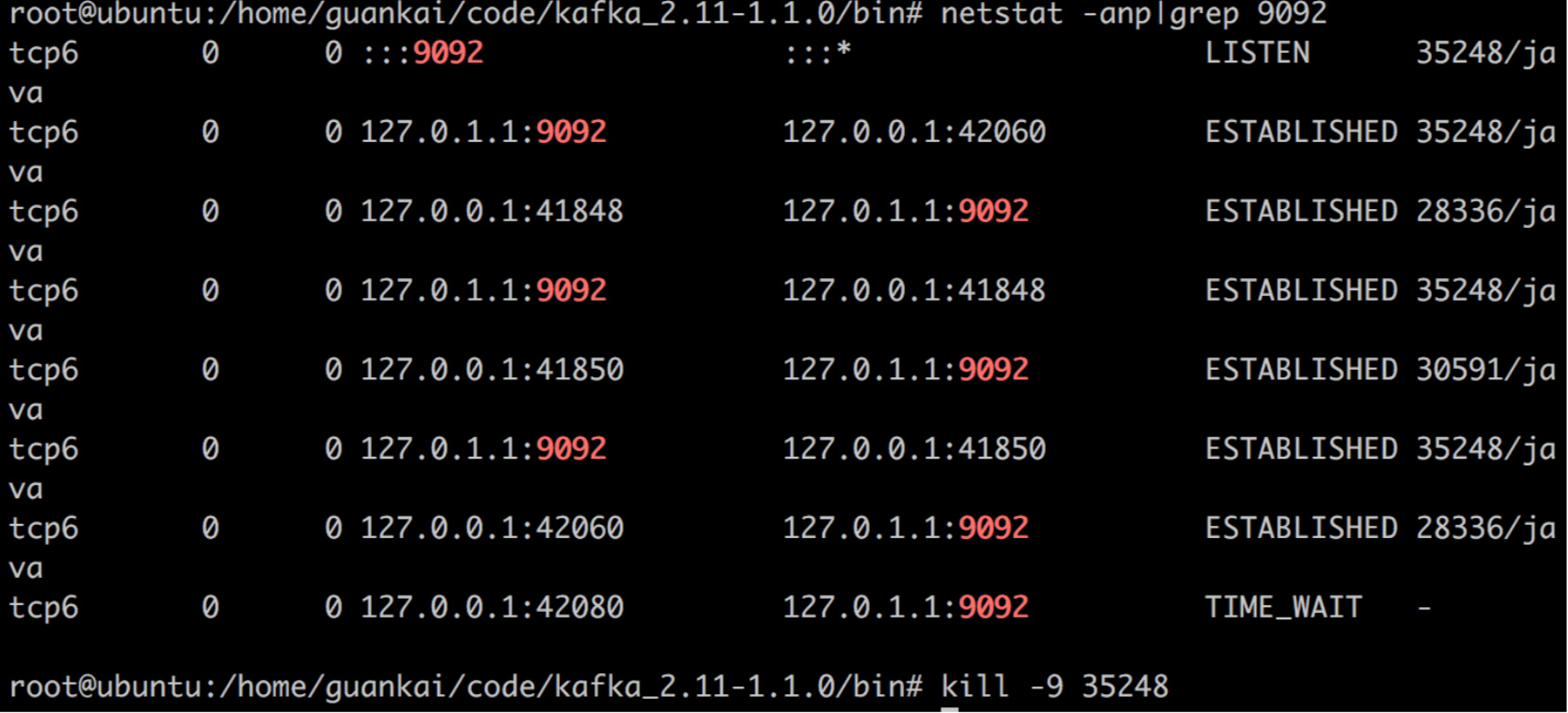
这个时候我们在看下这个topic的状态

由于broker 0已经停掉了,所以Irs同步备份的节点只剩下1,2。同时之前做leader的0也变成了1
这时候我们再从topic中消费消息

依然可以获取到,可见集群的容错。

